1 Computer Vision
(1.1) 3D Vision
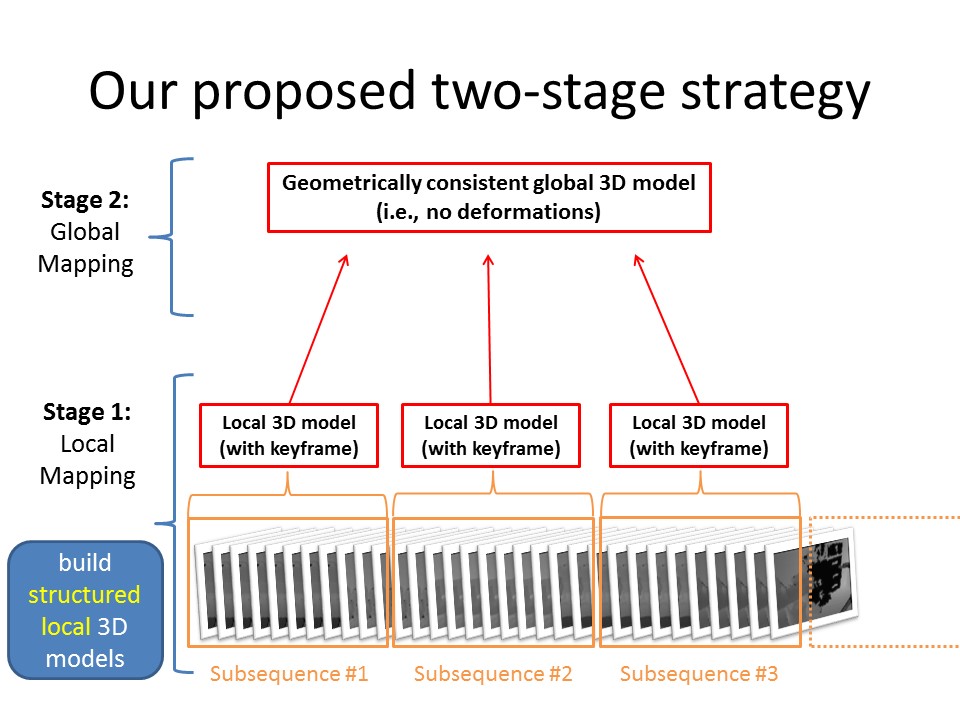
A Two-Stage Strategy for Real-Time Dense 3D Reconstruction of Large-Scale Scenes
The frame-to-global-model approach is widely used for accurate 3D modeling from sequences of RGB-D images. Because still no perfect camera tracking system exists, the accumulation of small errors generated when registering and integrating successive RGB-D images causes deformations of the 3D model being built up. In particular, the deformations become signi cant when the scale of the scene to model is large. To tackle this problem, we propose a two-stage strategy to build in details a large-scale 3D model with minimal deformations where the first stage creates accurate small-scale 3D scenes in real-time from short subsequences of RGB-D images while the second stage re-organises all the results from the first stage in a geometrically consistent manner to reduce deformations as much as possible. By employing planar patches as the 3D scene representation, our proposed method runs in real-time to build accurate 3D models with minimal deformations even for large-scale scenes.
References:
- A two-Stage Strategy for Real-Time Dense 3D Reconstruction of Large-Scale Scenes
- Proc. of the 4th IEEE Workshop on Consumer Depth Cameras for Computer Vision (CDC4CV2014), 2014.
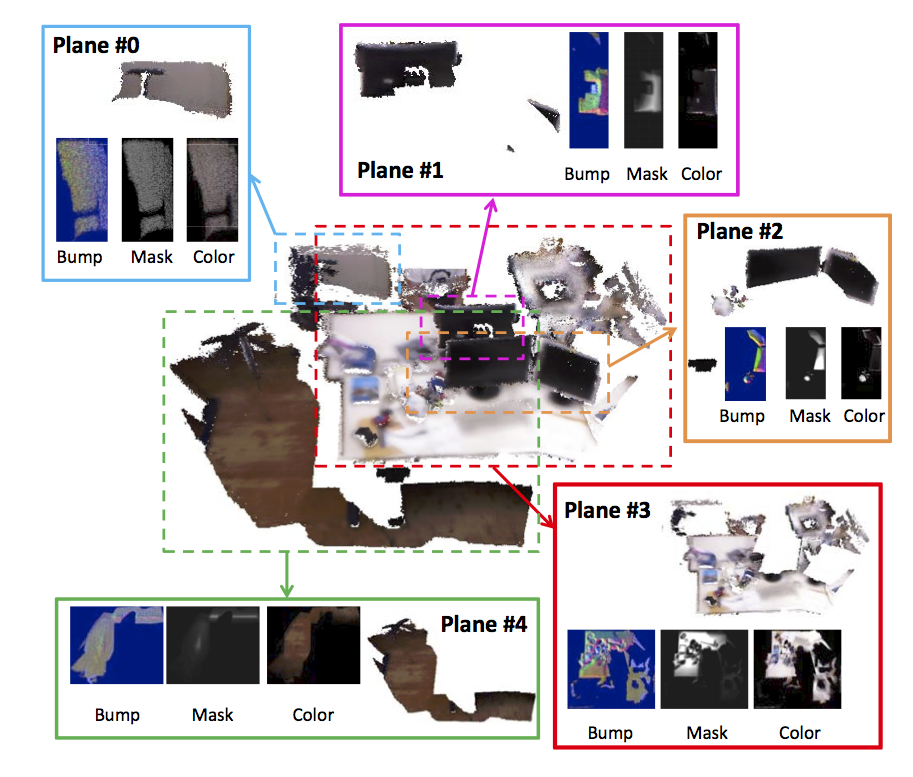
Flexible Scene Representation for 3D Reconstruction Using an RGB-D Camera
Updating a global 3D model with live RGB-D measurements has proven to be successful for 3D reconstruction of indoor scenes. Recently, a Truncated Signed Distance Function (TSDF) volumetric model and a fusion algorithm have been introduced (KinectFusion), showing significant advantages such as computational speed and accuracy of the reconstructed scene. This algorithm, however, is expensive in memory when constructing and updating the global model. As a consequence, the method is not well scalable to large scenes. We propose a new flexible 3D scene representation using a set of planes that is cheap in memory use and, nevertheless, achieves accurate reconstruction of indoor scenes from RGB-D image sequences. Projecting the scene onto different planes reduces significantly the size of the scene representation and thus it allows us to generate a global textured 3D model with lower memory requirement while keeping accuracy and easiness to update with live RGB-D measurements. Experimental results demonstrate that our proposed flexible 3D scene representation achieves accurate reconstruction, while keeping the scalability for large indoor scenes.
References:
- A Flexible Scene Representation for 3D Reconstruction Using an RGB-D Camera PDF
- Proc. of the 14th IEEE International Conference on Computer Vision (ICCV2013), pp. 2800-2807, 2013.
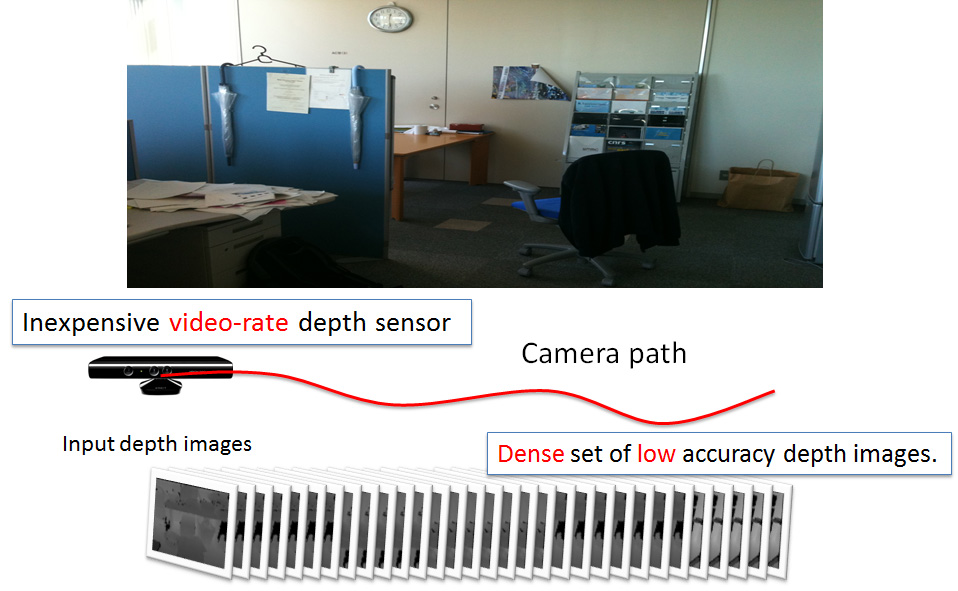
Robust Simultaneous 3D Registration via Rank Minimization
We present a robust and accurate 3D registration method for a dense sequence of depth images taken from unknown viewpoints. Our method simultaneously estimates multiple extrinsic parameters of the depth images to obtain a registered full 3D model of the scanned scene. By arranging the depth measurements in a matrix form, we formulate the problem as a simultaneous estimation of multiple extrinsics and a low-rank matrix, which corresponds to the aligned depth images as well as a sparse error matrix. Unlike previous approaches that use sequential or heuristic global registration approaches, our solution method uses an advanced convex optimization technique for obtaining a robust solution via rank minimization. To achieve accurate computation, we develop a depth projection method that has minimum sensitivity to sampling by reading projected depth values in the input depth images. We demonstrate the effectiveness of the proposed method through extensive experiments and compare it with previous standard techniques.
References:
- Robust Simultaneous 3D Registration via Rank Minimization PDF
- Proc. Symposium on 3D Imaging, Modeling, Processing, Visualization and Transmission (3DIMPVT2012), pp. 33--40, Zurich, Switzerland, 2012.
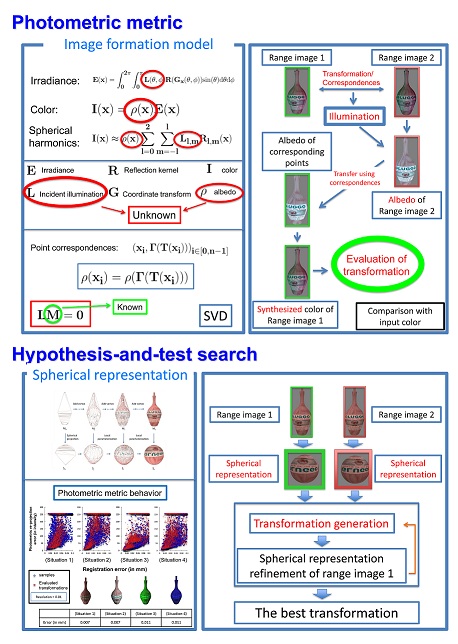
Range Image Registration using a Photometric Metric under Unknown Lighting
This paper presents an illumination-free photometric metric for evaluating the goodness of a rigid transformation aligning two overlapping range images, under the assumption of Lambertian surface. Our metric is based on photometric re-projection error but not on feature detection and matching. We synthesize the color of one image using albedo of the other image to compute the photometric re-projection error. The unknown illumination and albedo are estimated from the correspondences induced by the input transformation using the spherical harmonics representation of image formation. This way allows us to derive an illumination-free photometric metric for range image alignment. We use a hypothesize-and-test method to search for the transformation that minimizes our illumination-free photometric function. Transformation candidates are efficiently generated by employing the spherical representation of each image. Experimental results using synthetic and real data show the usefulness of the proposed metric.
References:
- Illumination-Free Photometric Metric for Range Image Registration PDF
- Proc. of IEEE Workshop on Application of Computer Vision (WACV2012), pp. 97--104, Corolado, USA, 2012.
- Range Image Registration using a Photometric Metric under Unknown Lighting PDF
- IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), Vol.35, No. 9, pp. 2252-2269, 2013.
(1.2) Gaze Estimation and Navigation
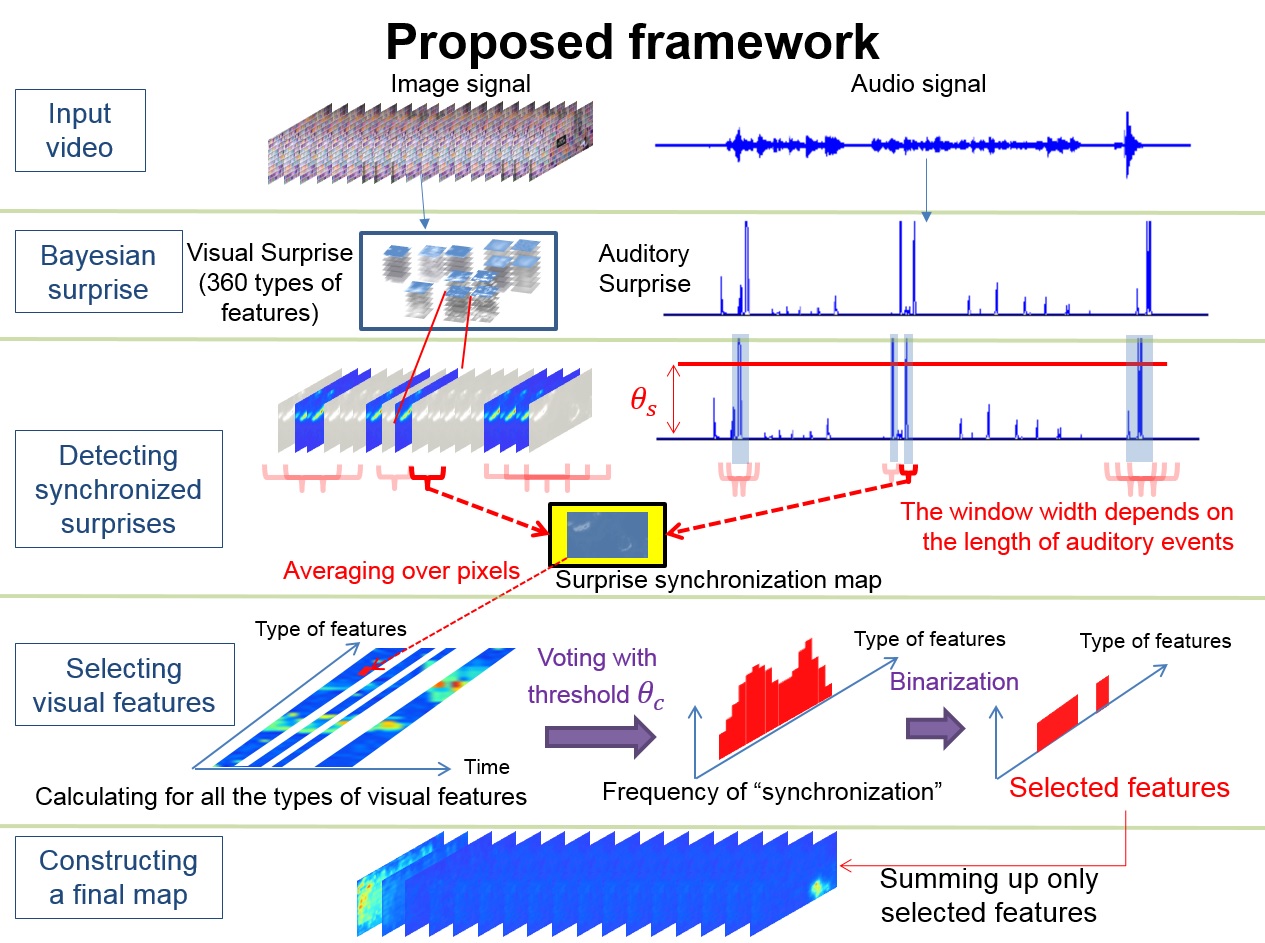
Visual Attention Driven by Auditory Cues
Human visual attention can be modulated not only by visual stimuli but also by ones from other modalities such as audition. Hence, incorporating auditory information into a human visual attention model would be a key issue for building more sophisticated models. However, the way of integrating multiple pieces of information arising from audio-visual domains still remains a challenging problem. This paper proposes a novel computational model of human visual attention driven by auditory cues. Founded on the Bayesian surprise model that is considered to be promising in the literature, our model uses surprising auditory events to serve as a clue for selecting synchronized visual features and then emphasizes the selected features to form the final surprise map. Our approach to audio-visual integration focuses on using effective visual features alone but not all available features for simulating visual attention with the help of auditory information.
References:
- Visual Attention Driven by Auditory Cues - Selecting Visual Features in Synchronization with Attracting Auditory Events PDF
- Proc. of MultiMedia Modeling - 21st International Conference (MMM 2015), pp. 74--86, 2015.
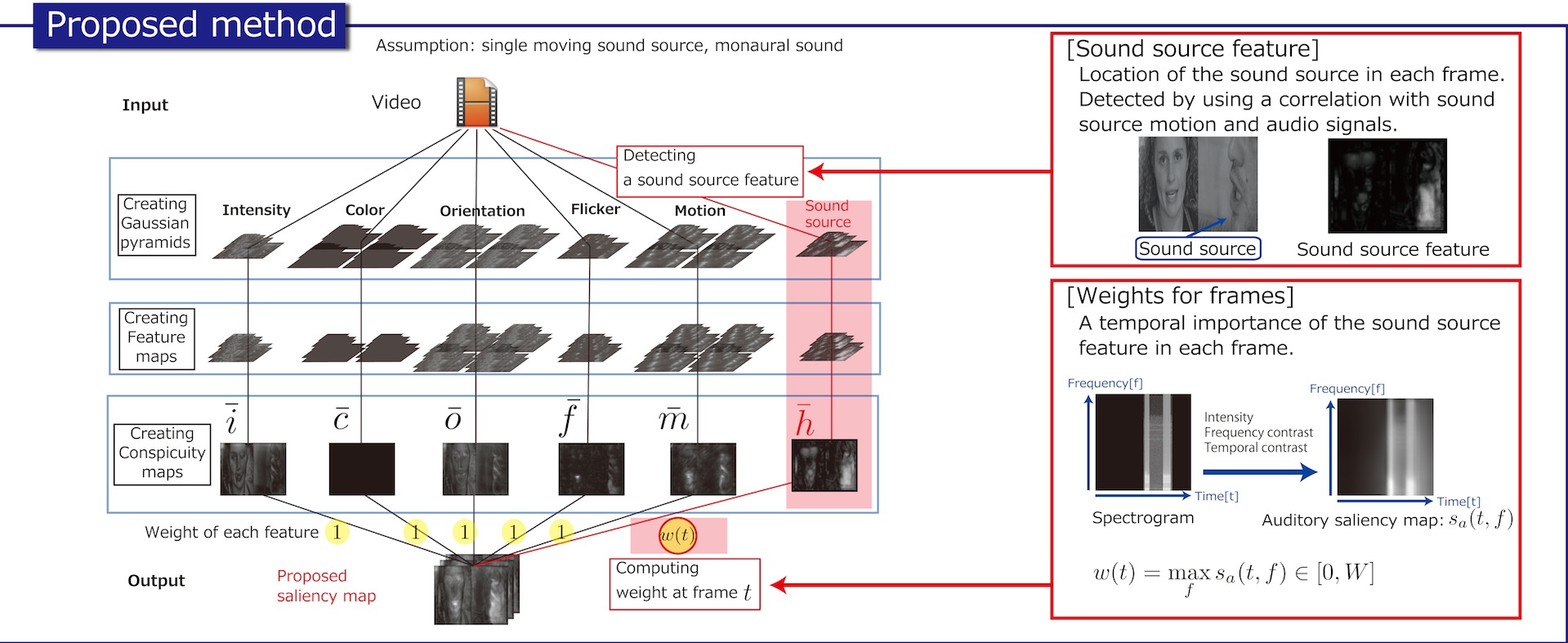
Incorporating Audio Signals into Constructing a Visual Saliency Map
The saliency map has been proposed to identify regions that draw human visual attention. Differences of features from the surroundings are hierarchially computed for an image or an image sequence in multiple resolutions and they are fused in a fully bottom-up manner to obtain a saliency map. A video usually contains sounds, and not only visual stimuli but also auditory stimuli attract human attention. Nevertheless, most conventional methods discard auditory information and image information alone is used in computing a saliency map. This paper presents a method for constructing a visual saliency map by integrating image features with auditory features. We assume a single moving sound source in a video and introduce a sound source feature. Our method detects the sound source feature using the correlation between audio signals and sound source motion, and computes its importance in each frame in a video using an auditory saliency map. The importance is used to fuse the sound source feature with image features to construct a visual saliency map. Experiments using subjects demonstrate that a saliency map by our proposed method reflects human’s visual attention more accurately than that by a conventional method.
References:
- Constructing a Visual Saliency Map Combined with Audio Signals
- International Joint Workshop on Advanced Sensing/Visual Attention and Interaction (ASVAI2013), Invited poster, 2013.
- Incorporating Audio Signals into Constructing a Visual Saliency Map
- Proc. of the 6th Pacific-Rim Symposium on Image and Video Technology (PSIVT2013), pp.468-480(LNCS 8333,Springer), 2013.

Saliency-Based Image Editing for Guiding Visual Attention
The most important part of an information system that assists human activities is a natural interface with human beings. Gaze information strongly reflects the human interest or their attention, and thus, a gaze-based interface is promising for future usage. In particular, if we can smoothly guide the user's visual attention toward a target without interrupting their current visual attention, the usefulness of the gaze-based interface will be highly enhanced. To realize such an interface, this paper proposes a method for editing an image, when given a region in the image, to synthesize the image in which the region is most salient. Our method first computes a saliency map of a given image and then iteratively adjusts the intensity and color until the saliency inside the region becomes the highest for the entire image. Experimental results confirm that our image editing method naturally draws the human visual attention toward our specified region.
References:
- Saliency-Based Image Editing for Guiding Visual Attention PDF
- Proc. of 1st Int. Workshop on Pervasive Eye Tracking and Mobile Eye-Based Interaction (PETMEI2011), pp. 43--48, Beijing, China, 2011.
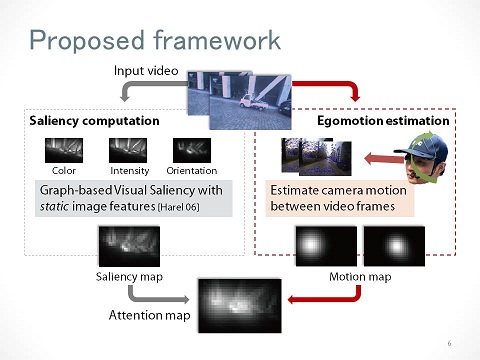
Attention Prediction in Egocentric Video using Motion and Visual Saliency
We propose a method of predicting human egocentric visual attention using bottom-up visual saliency and egomotion information. Computational models of visual saliency are often employed to predict human attention; however, its mechanism and effectiveness have not been fully explored in egocentric vision.
The purpose of our framework is to compute attention maps from an egocentric video that can be used to infer a person's visual attention. In addition to a standard visual saliency model, two kinds of attention maps are computed based on a camera's rotation velocity and direction of movement. These rotation-based and translation-based attention maps are aggregated with a bottom-up saliency map to enhance the accuracy with which the person's gaze positions can be predicted.
The efficiency of the proposed framework was examined in real environments by using a head-mounted gaze tracker, and we found that the egomotion-based attention maps contributed to accurately predicting human visual attention.
References:
- Attention Prediction in Egocentric Video Using Motion and Visual Saliency PDF
- Proc. of The 5th Pacific-Rim Symposium on Image and Video Technology (PSIVT2011), pp. 277--288 (LNCS Vol. 7087, Springer), Gwangju, Korea, 2011.
(1.3) Image Categorization
.jpg)
Scale-Optimized Textons for Image Categorization and Segmentation
Texton is a representative dense visual word and it has proven its effectiveness in categorizing materials as well as generic object classes. Despite its success and popularity, no prior work has tackled the problem of its scale optimization for a given image data and associated object category. We propose scale-optimized textons to learn the best scale for each object in a scene, and incorporate them into image categorization and segmentation. Our textonization process produces a scaleoptimized codebook of visual words. We approach the scaleoptimization problem of textons by using the scene-context scale in each image, which is the effective scale of local context to classify an image pixel in a scene. We perform the textonization process using the randomized decision forest which is a powerful tool with high computational efficiency in vision applications. Our experiments using MSRC and VOC 2007 segmentation dataset show that our scale-optimized textons improve the performance of image categorization and segmentation.
References:
- Scale-Optimized Textons for Image Categorization and Segmentation PDF
- Proc. of IEEE International Symposium on Multimedia (ISM2011), pp. 257--262, California, USA, 2011.